Automating Hyperscale Efficiency: A Step-by-Step Guide to Meta's AI-Powered Capacity Optimization
Introduction
At Meta, serving over three billion users means that even a 0.1% performance regression can translate into massive power consumption. Traditional efficiency efforts—both offensive (proactive optimization) and defensive (regression detection)—worked well for years, but they created a new bottleneck: human engineering time. To break through, Meta built a unified AI agent platform that encodes domain expertise and automates the entire efficiency lifecycle. This guide walks through the exact steps Meta took to achieve a self-sustaining capacity efficiency engine, recovering hundreds of megawatts of power and compressing hours of manual investigation into minutes.

This step-by-step plan draws directly from Meta’s production-tested approach. By following it, you can adapt similar principles to your own large-scale infrastructure.
What You Need
- AI Agent Platform – A unified system where agents can execute skills across a standardized tool interface.
- Domain Expertise Encoding – The ability to capture senior engineers' efficiency knowledge as reusable, composable skills.
- Regression Detection System – A tool like Meta's FBDetect that automatically catches performance regressions in production.
- Automated Mitigation Pipeline – Capability to turn opportunity detection into ready-to-review pull requests without human intervention.
- Scalable Compute & Monitoring – Infrastructure to run agents at scale and collect performance metrics across thousands of services.
- Cross-Functional Buy-In – Support from engineering, operations, and product teams to adopt AI-driven workflows.
Step 1: Establish a Two-Sided Efficiency Framework
Before layering AI, Meta formalized efficiency as two complementary efforts:
- Offense – Proactively search for opportunities to make existing systems more efficient (e.g., code refactoring, algorithm improvements). Once found, these changes are deployed to production.
- Defense – Monitor resource usage in production to detect regressions as they occur, root-cause them to a specific pull request, and deploy mitigations.
Having this clear split ensures that AI agents can be specialized for each side: one set focuses on opportunity discovery, another on regression remediation.
Step 2: Build a Unified AI Agent Platform
Create a single platform where agents can access all the tools and data needed to diagnose and fix issues. Meta’s platform standardizes the interface so that agents can call any tool (e.g., performance profilers, cost calculators, code repositories) using a common protocol. This unification is critical because it prevents agent fragmentation and allows skills to be reused across products.
Design the platform with:
- Standardized API contracts for all infrastructure tools.
- Centralized logging and observability to track agent actions.
- Safety guardrails so agents cannot deploy changes without human review.
Step 3: Encode Domain Expertise into Reusable Skills
Senior efficiency engineers have deep knowledge about common performance patterns, typical regressions, and effective mitigation strategies. Instead of letting that expertise remain tacit, Meta encodes it into reusable, composable skills that agents can execute autonomously.
For each skill:
- Document the trigger condition (e.g., a sudden spike in CPU usage).
- Define the diagnostic steps (e.g., which profiler to run, which metrics to compare).
- Specify the fix (e.g., a code change that reverts a problematic commit or adds caching).
By composing multiple skills, agents can handle complex scenarios that previously required hours of manual investigation.
Step 4: Implement Defense with Regression Detection Automation
Meta uses FBDetect, an in-house regression detection tool, as the backbone of its defense system. This tool catches thousands of regressions weekly. The key is to connect FBDetect to the AI agent platform so that when a regression is flagged, the appropriate agent is automatically invoked.
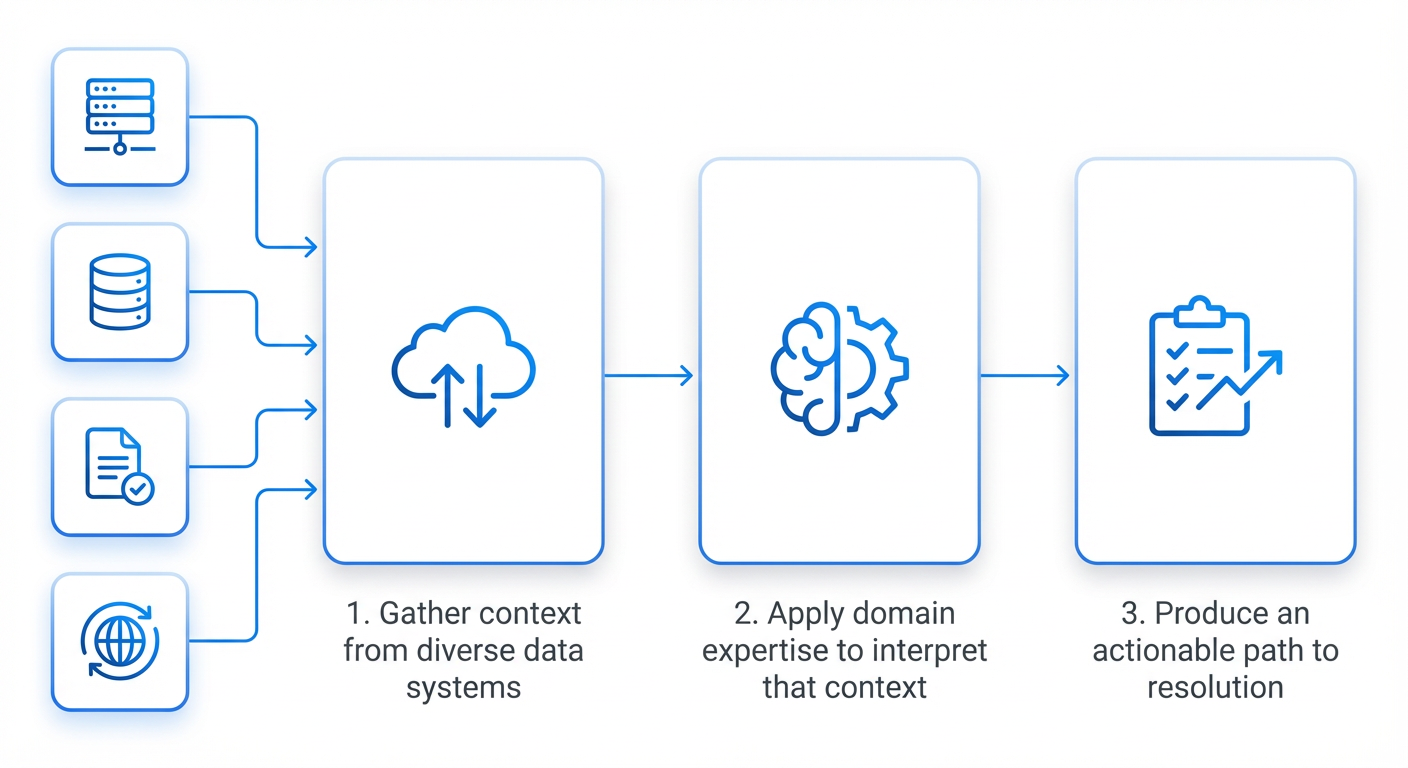
Steps to replicate:
- Integrate FBDetect (or equivalent) with your agent platform via webhooks.
- Have the agent automatically run diagnostic skills to isolate the root-cause pull request.
- Generate a mitigation PR and route it for human approval within minutes.
This reduces the time from detection to resolution from ~10 hours to ~30 minutes, drastically limiting the megawatts wasted while the regression compounds fleet-wide.
Step 5: Automate Offense with Opportunity Discovery Agents
On the offensive side, AI agents now proactively scan codebases and infrastructure for efficiency opportunities that human engineers might never get to. Meta reports that this approach is expanding to more product areas every half, handling a growing volume of wins.
Implementation approach:
- Train agents to identify common energy-heavy patterns (e.g., unnecessary loops, oversized data structures).
- Let agents automatically generate pull requests that implement the optimization, then present them for review.
- Track the power savings (in megawatts) from each accepted PR to measure impact.
Step 6: Create a Self-Sustaining Efficiency Engine
The end goal is a system where AI handles the long tail of efficiency issues, continuously learning and improving. Meta’s platform is designed to be self-sustaining:
- Agents that successfully fix regressions or discover optimizations are reinforced with updated skill weights or new composed skills.
- New domain expertise from senior engineers is rapidly encoded into the skill library.
- The program scales megawatt delivery without proportionally scaling headcount.
Tips for Success
- Start small, scale fast. Begin with one high-impact area (e.g., a specific data center or service) before rolling out to all products.
- Measure everything. Track power savings, engineer time saved, and regression time-to-fix. Use these metrics to demonstrate ROI.
- Keep humans in the loop. Always require human approval for code changes; agents should only propose fixes, not deploy them autonomously.
- Invest in skill diversity. The more varied the encoded expertise, the more scenarios your agents can handle.
- Update skills regularly. As infrastructure evolves, stale skills can cause false positives or missed opportunities.
By following these steps, any organization operating at scale can build its own version of Meta’s Capacity Efficiency Program. The result is not just power savings—it’s freeing engineers to focus on innovation rather than firefighting performance regressions.
Related Articles
- 8 Things You Need to Know About gThumb's Stunning GTK4/libadwaita Overhaul
- Linux Security and Innovation: Kernel Killswitch, Fedora AI, and More Open Source Updates
- How to Diagnose and Fix a CUBIC Congestion Control Bug in QUIC
- Fedora 44: GNOME 50 Goes Stable with VRR, Plasma 6.6 Adds OCR, and More
- How to Deploy and Use Fedora Hummingbird for Secure, Rolling Container Images
- Fedora Asahi Remix 44 Brings Fedora Linux to Apple Silicon Macs with Enhanced Features
- LWN.net Weekly Edition: April 30, 2026 - In-Depth Q&A
- How to Apply Critical Security Updates on Major Linux Distributions